Mesh Subdivision
Mesh Subdivision 是一种将模型进行分割的方法,增加模型的三角形面,使得模型更加平滑。当一个物体距离相机非常近的时候,我们希望这个物体的细节更加丰富。
 我们的细分通常是指对一个原有的三角形面划分出更多的三角形,再使得这些三角形的顶点发生一点变换使得模型更精细。如果只做一步细分,但是顶点没变,那不是相当于什么都没做吗?
我们的细分通常是指对一个原有的三角形面划分出更多的三角形,再使得这些三角形的顶点发生一点变换使得模型更精细。如果只做一步细分,但是顶点没变,那不是相当于什么都没做吗?
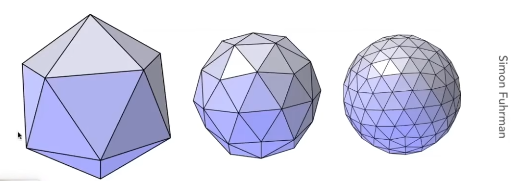
Loop Subdivision
以Loop Subdivision为例
第一步将三角形的数量增多
很简单,将三角形的三个边的中点连接起来就能得到一个新的三角形
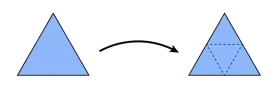
调整三角形顶点的位置
我们的顶点区分为新的顶点和旧的顶点,新的顶点就是细分前三角形的顶点,旧的顶点就是细分后多出来的顶点。 而Loop Subdivision对于这两种顶点进行不同的规则进行调整
- 我们先来看看看怎么调整新的顶点的位置
对于下图中白色的顶点,只要这个顶点不是三角形的边界(一般不会是边界)那么他一定会被两个三角形共有, 对于旧的三角形的顶点ABCD,其中有两个是共享的顶点AB,有两个不共享的顶点CD,那么对于这个新的白色的顶点来说它的位置应该是 $$\frac{3}{8}(A+B)+\frac{1}{8}(C+D)$$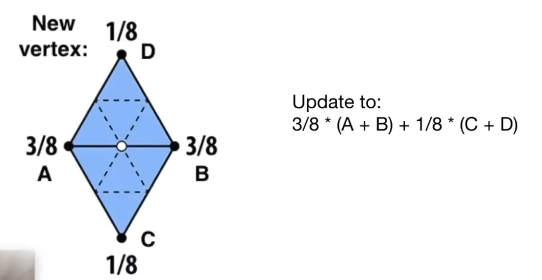
- 我们再来看怎么调整旧的顶点位置
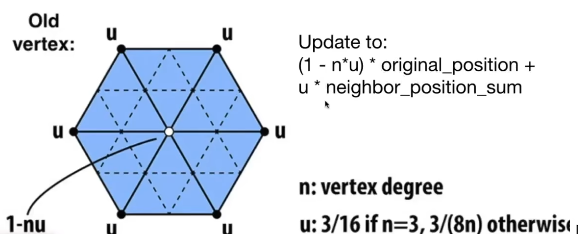
对于下图中白色的点$\mathbf{P}$,它是这么更新的 $$(1-nu)\mathbf{P} + u\mathbf{NeighbourPointSum}$$
- 其中$n$是这个点$P$的度
- $u$: $$u=\left\{\begin{matrix} \frac{3}{16} & n=3 \\ \frac{3}{8n} &otherwise \end{matrix}\right.$$
- $\mathbf{NeighbourPointSum}$是这个白色的点的周围的旧顶点
Catmull-Clark Subdivision
Loop Subdivision 的问题在于只能对三角形网格进行细分,而对于其他的网格不行,而Catmull-Clark Subdivision 可以对任意的网格进行细分 我们先来了解几个不需要解释也能懂的概念
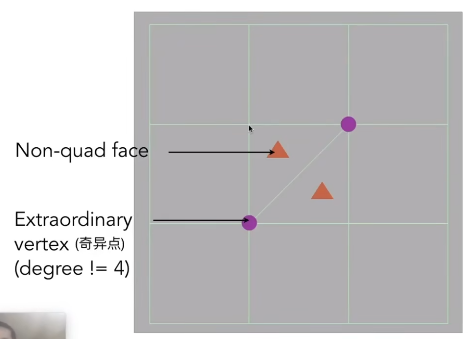
- 四边形面
- 非四边形面
- 奇异点 :度不等于4的点
 同样我们需要进行两步细分和调整
同样我们需要进行两步细分和调整
- 细分
对于每个边我们取它的中点,对于每一个面我们也取它的“中点”,我们把这些点连起来
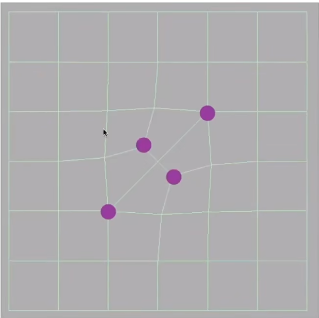 经过了一次细分后,多了两个奇异点,少了两个非四边形面,已经没有非四边形面了,可以说非四边形面和奇异点互换了。我们可以发现只要我们在非四边形网格中点上一个点,由于这个点要和这个非四边形的边相连,而这个非四边形的边一定不是4,所以这么一连得到一个度不是4的点一定是奇异点。由于我们的非四边形面已经没有了,已经做不了转换了,所以在没有非四边形面的情况下再进行一次细分不会引入新的奇异点
经过了一次细分后,多了两个奇异点,少了两个非四边形面,已经没有非四边形面了,可以说非四边形面和奇异点互换了。我们可以发现只要我们在非四边形网格中点上一个点,由于这个点要和这个非四边形的边相连,而这个非四边形的边一定不是4,所以这么一连得到一个度不是4的点一定是奇异点。由于我们的非四边形面已经没有了,已经做不了转换了,所以在没有非四边形面的情况下再进行一次细分不会引入新的奇异点
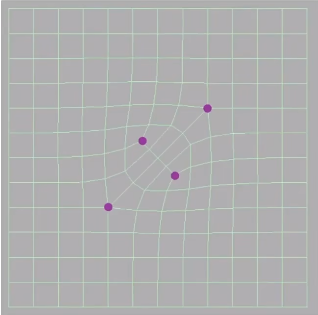
- 调整 在 Catmull-Clark Subdivision 中顶点的调整分为3类
- 新的顶点
- 点在面中间的点
- 点在边中间的点
- 旧的顶点
对于点在面中间的点
$$f = \frac{v_1+v_2+v_3+v_4}{4}$$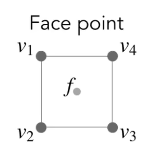 对于点在边中间的点
对于点在边中间的点
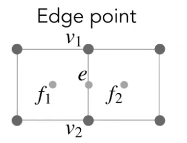 对于旧的顶点
对于旧的顶点
其中p是这个旧的点本身
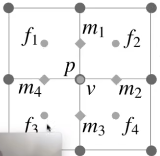
Mesh Simplification
Mesh Simplification 是一种将模型进行简化的方法,减少模型的三角形面,使得模型更加简单。
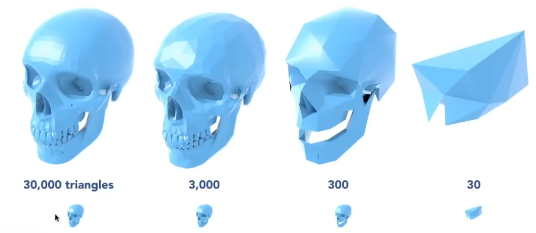
 当一个物体距离我们摄像机很远的时候,我们几乎看不清模型的细节,我们希望这个物体更加简单,这样我们就可以减少模型的计算量,提高渲染效率。通过下面这幅图的对于,对于小的模型来说30000个三角形和3000个三角形,我们根本看不出区别,这和我们的Mipmap非常的像,对于一个远的像素来说我们不需要那么精细的纹理,这是一个几何的层次结果。我们需要做好模型层级结构的与相机距离的切换,在什么时候切换,切换的时候会不会看到明显的变换
当一个物体距离我们摄像机很远的时候,我们几乎看不清模型的细节,我们希望这个物体更加简单,这样我们就可以减少模型的计算量,提高渲染效率。通过下面这幅图的对于,对于小的模型来说30000个三角形和3000个三角形,我们根本看不出区别,这和我们的Mipmap非常的像,对于一个远的像素来说我们不需要那么精细的纹理,这是一个几何的层次结果。我们需要做好模型层级结构的与相机距离的切换,在什么时候切换,切换的时候会不会看到明显的变换
Edge Collapsing
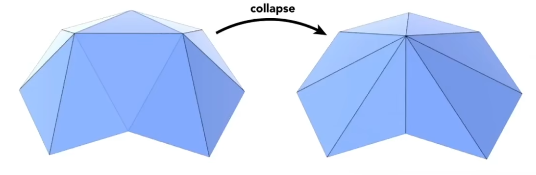
Edge Collapsing 是一种简化模型的操作,的思想非常简单我们可以让一个边上的两个顶点同时以相同的速度向中间靠拢,合并成一个点
 但是我们需要考虑一些问题,哪些边不重要需要坍缩,哪些边重要不能坍缩,
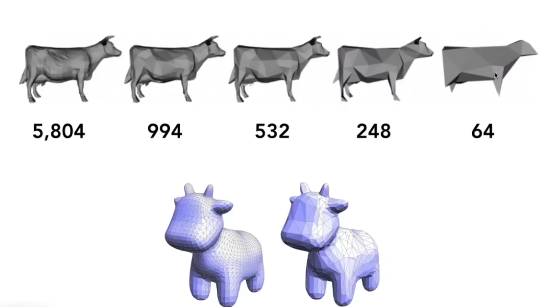
我们先来看看下面图中左边的这副图,我们不想要这副图的第2和4个点了,第我们直接对原来的五个点进行平均得到一个新的点,作为原来的第3个点的新的位置,但是我们发现这和原来的模型比起来非常不对,这时候我们就需要使用Quadric Error Metric,其实就是机器学习中的平方误差,而Quadric Error Metric 的目的就是找到一个点,让这个新的点的位置距离原来四个面的距离的平方和最小
但是我们需要考虑一些问题,哪些边不重要需要坍缩,哪些边重要不能坍缩,
我们先来看看下面图中左边的这副图,我们不想要这副图的第2和4个点了,第我们直接对原来的五个点进行平均得到一个新的点,作为原来的第3个点的新的位置,但是我们发现这和原来的模型比起来非常不对,这时候我们就需要使用Quadric Error Metric,其实就是机器学习中的平方误差,而Quadric Error Metric 的目的就是找到一个点,让这个新的点的位置距离原来四个面的距离的平方和最小
 对于一个三维模型,我们可以每次坍缩Quadric Error Metric中最小的一个边,知道遍历完所有的边
对于一个三维模型,我们可以每次坍缩Quadric Error Metric中最小的一个边,知道遍历完所有的边
Shadows
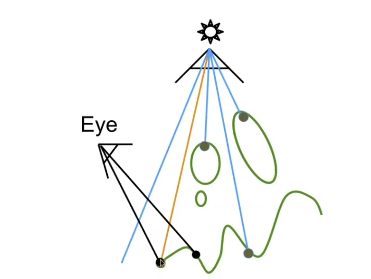
我们在光栅化进行着色的时候我们是只考虑Shading Point的,对于其他的事物我们完全没有考虑,但事实上这是不对的,因为如果有其他物体挡在了Shading Point和光源之间的话,那么这个Shading Point应该是在阴影Shadow之间的,这个Shading Point应该是暗的
Shadow Mapping
 Shadow Mapping的思想非常简单,他的思想原理非常简单,如果一个Shading Point能被光源看到(直射)并且也能被摄像机看到,那么这个点就在光照下(不在阴影中),反之如果一个点只能被摄像机看到,而不能被光源看到,那么他就在阴影中。
这里很重要的就是能被光源看到,所以我们的做法就是模拟这种过程
Shadow Mapping的思想非常简单,他的思想原理非常简单,如果一个Shading Point能被光源看到(直射)并且也能被摄像机看到,那么这个点就在光照下(不在阴影中),反之如果一个点只能被摄像机看到,而不能被光源看到,那么他就在阴影中。
这里很重要的就是能被光源看到,所以我们的做法就是模拟这种过程
Pass 1:Render from Light
我们先从光源的位置看向场景,并且生成一张Depth Map
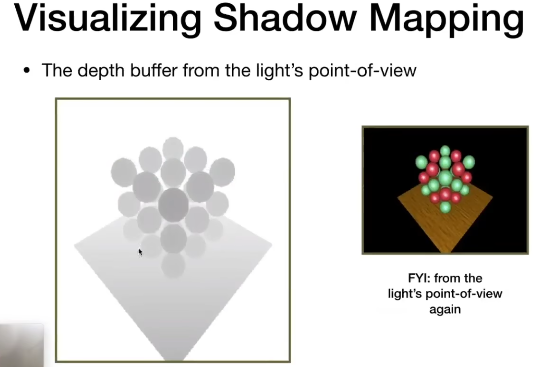
Pass 2:Render from Camera
我们从摄像机的位置看向场景,此时我们可以计算光源与Shading Point之间的距离,并且使用之前从光源角度出发生成的Depth Map来判断这个点是否在阴影中,如果Shading Point到光源的距离大于Depth Map中的距离,这个点就在阴影中,反之则不在阴影中